
Machine learning: $k$-nearest neighbors.
I spent the last couple of days working on the applciation for the TA position at this May’s data science bootcamp. Most of it was very basic questions like writing one-line commands and diagnosing and fixing code with errors. One question tested list comprehension (I still need to do a post on that – maybe tomorrow?). Then near the end was a problem where I had to apply the $k$-nearest neighbors ($k$NN) algorithm to some manufactured data! No machine learning background required, according to the application, since there was documentation for the Python module that would be used. It was challenging, like I said I spent 2 days on it, but I did learn something.
So what is $k$NN? It’s a classification algorithm, and it falls into supervised learning. Here’s the idea. You have a set of features, and one of them is categorical. There is a relationship between the categorical feature and the rest of the features, and so $k$NN uses the other features to predict which category each sample falls under. A famous example of a data set where this algorithm would be used is the iris data set. In fact, this data set is used by a lot of data scientists for testing classification algorithms. Each sample is a flower (iris), and the features include its petal length, sepal length, petal width, sepal width, and the class of iris it is (setosa, versicolor, or virginica). We train the petal and sepal data to predict the class.
So how does it work? First you plot all of the non-categorical features against each other. Then for each data point, record its category, along with the categories of the $k$ data points that are closest to it (in the TA application I had to use $k=5$). Then the predicted category is the one that shows up the most times. Matt says if there is a tie then the winner is chosen at random, but I believe there are actual algorithms that can break ties. And that’s it!
Here is a visualization from my application. The non-categorical features are in the variable $X$, and there are two of them plotted against each other. The variable $y$ can take on the value either $0$ or $1$. I’ve color-coded the data points according to category.
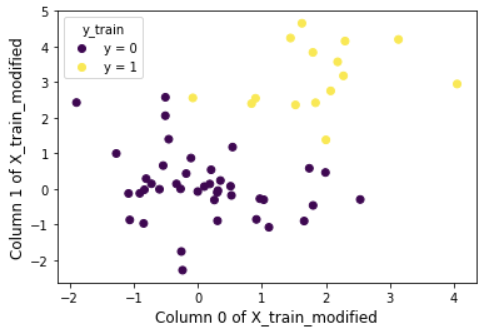
(The axes are so-labelled because in splitting the data I had to make a modification.) The algorithm determines what color each dot should be, according to the colors of its closest neighbors.
There is a Python module that will do $k$NN, called sklearn.neighbors. From there, it’s just a few lines of code to run the algorithm. Here it is, after splitting the data into train data and test data. X_train is the train data for the non-categorical features and y_train is the train data for the categorical feature we wish to predict.
from sklearn.neighbors import KNeighborsClassifier
# Make the model object (k=5)
knn = KNeighborsClassifier(5)
# "Fit" the model object
knn.fit(X_train, y_train)
# Predict on the training set
y_pred = knn.predict(X_train)
I used accuracy_score from the sklearn.metrics module to see how well my algorithm did and it gave me a 1.0, a perfect score. Of course I thought this was fishy, so I decided to run the algorithm “by hand” and see if I got the same answer. I used the NearestNeighbors object to get a list of indices in X_train with the indices of their nearest neighbors. Then I recorded the category of each sample and took the one that appeared the most in each case and added it to my y_pred array. Then I asked Python if y_pred == y_train, and it said all values were equal! So I’m glad the result was consistent. Maybe I still did something wrong but I’m hoping that checking the algorithm by hand will make my application look better, since it was a little above and beyond.
Overall I’m pretty satisfied with my TA application. I haven’t submitted it yet, I sent Matt a Slack message when I was done, asking if I could get clarification, so we’ll see what he says. There were a lot of questions that came up as I was filling it out, but I tried to do the problems to the best of my ability. Maybe I’ll do a post about the questions I had and how I tried to answer them. Still want to do a post about list comprehension. In my application there was an opportunity to do a nested list comprehension. I didn’t, since I thought it would make the code harder to read, but I’m kind of curious to see if I could’ve made it work.