
New project.
This past week has been spent working on the new project. Coming up with a new topic seemed daunting, so I took the rest of last Friday off and started looking on Saturday. But I felt like after getting all that experience scraping data on the last project attempt my options for where to get data were more open. I got this idea that I would analyze the posts of Fox News and MSNBC against the number of comments and write an algorithm to predict which topics would get more traffic. Unfortunately MSNBC doesn’t have a comments section. I read that a lot of news sites are getting rid of comments under the rationale that a toxic comments section will discredit the article. I tried to look at other news sites and it seemed to be true. Ultimately I decided I would just get my data from the 538 politics section. It has comments and the posts already have tags so I don’t need to do any advanced NLP to get the topics.
Scraping the data from 538 seemed pretty easy at first. In less than 2 hours I wrote a script that would go through however many pages of headlines I want and for each article scrape the title, url, author(s), date and time posted, and tags. Then came the VERY hard part: scraping the number of comments for each article. The comments on 538 are in the Facebook comments plugin and I learned that Facebook REALLY doesn’t want anyone to scrap their data. It’s not like I was asking for much, I just wanted the number of comments, nothing else.
I tried the most obvious thing first, using “inspect element” to find where in the source code to scrape, then using requests and BeautifulSoup. But that didn’t work because the source code was not matching what was in the “inspect element” frame. Matt said it was probably because there is a button on each page to show the comments section, and the source code has to update itself once the JavaScript on the page is rendered after clicking that button. So I tried clicking the button and waiting, and the source code did update, but not fully. A new tag appeared called <iframe>, but there was nothing in it. Its attributes contained a url so I tried pasting it into a new browser tab and got a blank page. Then I looked at the source code for the blank page and it was all a wall of JavaScript.
I did some Googling around on the problem and I learned that there are python modules that will force the JavaScript on a webpage to render. Of course, requests and BeautifulSoup can’t do it. But I found another module called selenium that seemed very popular. Unfortunately Matt has never used it, and he said he couldn’t really help me with it. He said I could try to read the documentation for it, or alternatively I could try to scrape the comments on 538’s Facebook page.
So I went with Matt’s Facebook idea. He said the comments on the 538 article should match the ones on the Facebook page, and then I could use a Facebook API to scrape them. Facebook does have an API called Graph, but I think it only works on Facebook pages you own. Instead I found a third party module called facebook-scraper that can get metadata for comments. Using it requires loading cookies, but there is a browser extension that allows you to save all your cookies on a site to a file. After I did that, the scraping tool was easy enough to use but then I ran into another problem. The number of comments returned from each post was not matching the number of comments I could see on the Facebook page, which also did not match the number of comments on the article page. I wanted to try to scrape a few of the comments themselves, to see where this count was coming from, but the documentation on facebook-scraper was very limited and it didn’t look like there was a way to do it, anyway.
So I decided to go back to selenium. During Matt’s office hours on Wednesday he had given me this idea to try a switch frame command that would load the webpage embedded in the article page (I had seen on the “inspect element” source that there was an entire index.html file embedded in the source code). It didn’t work, and we were both unsure of how to use it anyway, but seeing that idea yesterday among all the other failed code I had commented out working on this project gave me another idea. And this is the idea that worked! I spent the rest of last night consolidating all of my scraping code and since scraping the number of comments was the hardest task I made a function that would do it.!
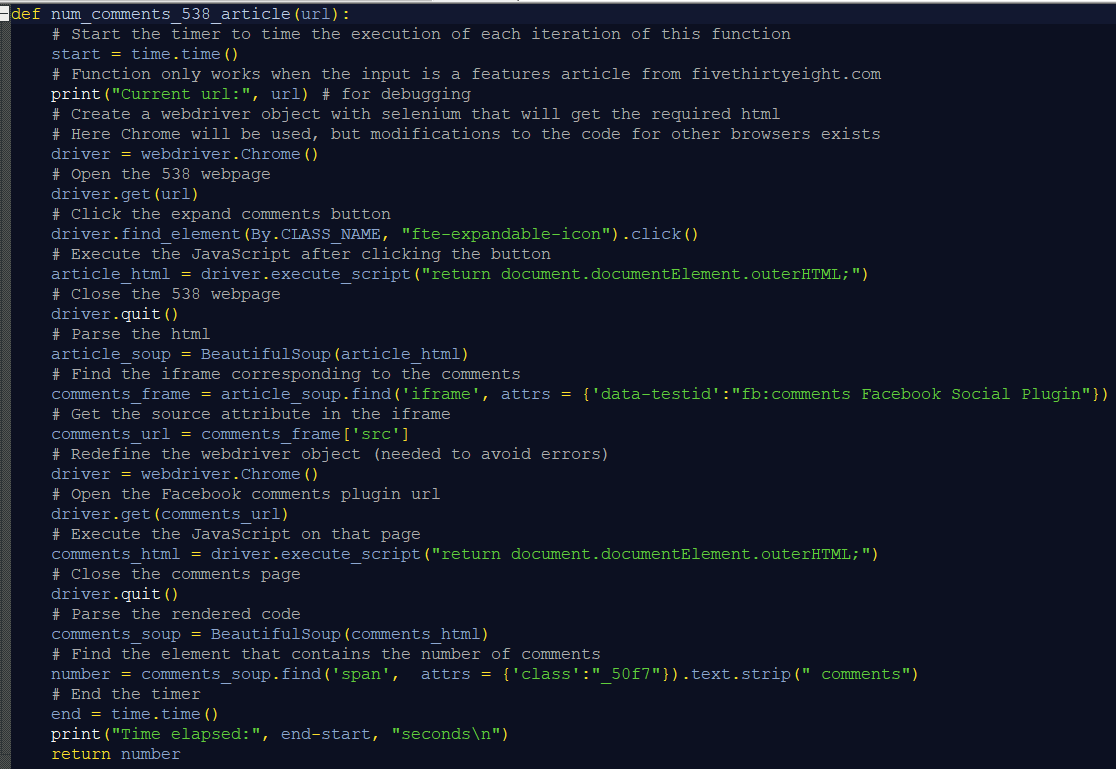
I’m still not sure how selenium works but at least I learned enough to get this to work. I found out it could be used to click buttons on webpages, too. The driver object is what opens the article and executes all the JavaScript on that page. Matt said I might be able to get rid of the first instance of driver.quit() and the second instance of driver = webdriver.Chrome() but when I tried commenting those lines out the code ran way too slow.
The code also has a lot of debugging commands like the timer and the line print("Current url:", url). Matt said instead of including all that extra code I could try a module called logging or something like that, but I haven’t looked into it yet. The code also originally had a failsafe to ensure the input was the url of a 538 article, but Matt said I didn’t need it since I’m the only one using the function. When I had it I thought I was trying to make the function as universal as possible, but I guess I don’t need to do that when I know for a fact it only works with 538 articles.
I showed Matt all of my code at his office hours this morning and he didn’t have too much feedback on the quality. I’d thought the main section was too long and that it might be better if I wrote more functions but Matt said I only need to write functions if I’m reusing chunks of code. I thought putting everything into functions was good practice, since it makes the code easier to read. I’m certainly glad I made the one function. But Matt said my main code wasn’t that long, anyway. And I think it’s all very well-annotated. Matt’s main feedback was that I need the code to get more data. Last night I ran it for 32 minutes and got data for 78 articles. Matt said I need closer to 500 and he suggested that I scrape data from podcast episodes and videos, too, right now the code filters those out and I’m not really sure why I made that decision. Matt also gave me some ideas of how I can proceed with the next step of the project, cleaning and processing the data. It’s been a week just trying to find a good project topic and gather the data for it but something tells me I’ve just finished the hardest part.