Preprocessing!
Yesterday I moved to the next phase of my project, data cleaning and preprocessing. I really didn’t have to do too much cleaning! Every time I thought of a way to make the data prettier I just incorporated it into the data gathering code.
At some point I wrote some code that would save the output of the data gathering code into a file with the name format (number of posts)-date-time.txt and put it in a folder with all the other output files. I thought about adding that folder to .gitignore, but maybe others might be interested in seeing how my code evolved, as I was perfecting it. At first the data files were a collection of lists, separated by whitespace. Turns out to write a list of lists to a file you have to write a loop that prints each nested list individually. Then I think I found a way to put commas between the lists. My next notebook, where I clean and preprocess the data, would only load the file as a string, so I started thinking I should save the output as a .csv file. This wasn’t easy at first, since my nested lists had further nested lists of the authors and tags for each post. But I found a way to make those nested lists into strings, with the commas replaced by semicolons. Now I was ready to save the data as a .csv file. The quickest way I could find to do it was to use pandas to make a data frame, then export that data frame to a .csv file. I don’t like that extra step of making the data frame, especially since I had to get rid of the index column so the next notebook wouldn’t create an extra one when I loaded it, but I had read from a Google search that this was the quickest way to do it. At Matt’s office hours on Wednesday I will ask if I can bypass that extra step somehow.
To test my preprocessing code I decided to gather 50 posts’ worth of data. Matt said utlitmately I should use 500 posts, but that would take a few hours to gather. I thought it would be a better idea to use the 50 posts on all the future code I write in this project, to quickly ensure the code works, then I could take the time to get all the data once I’m ready to complete the project.
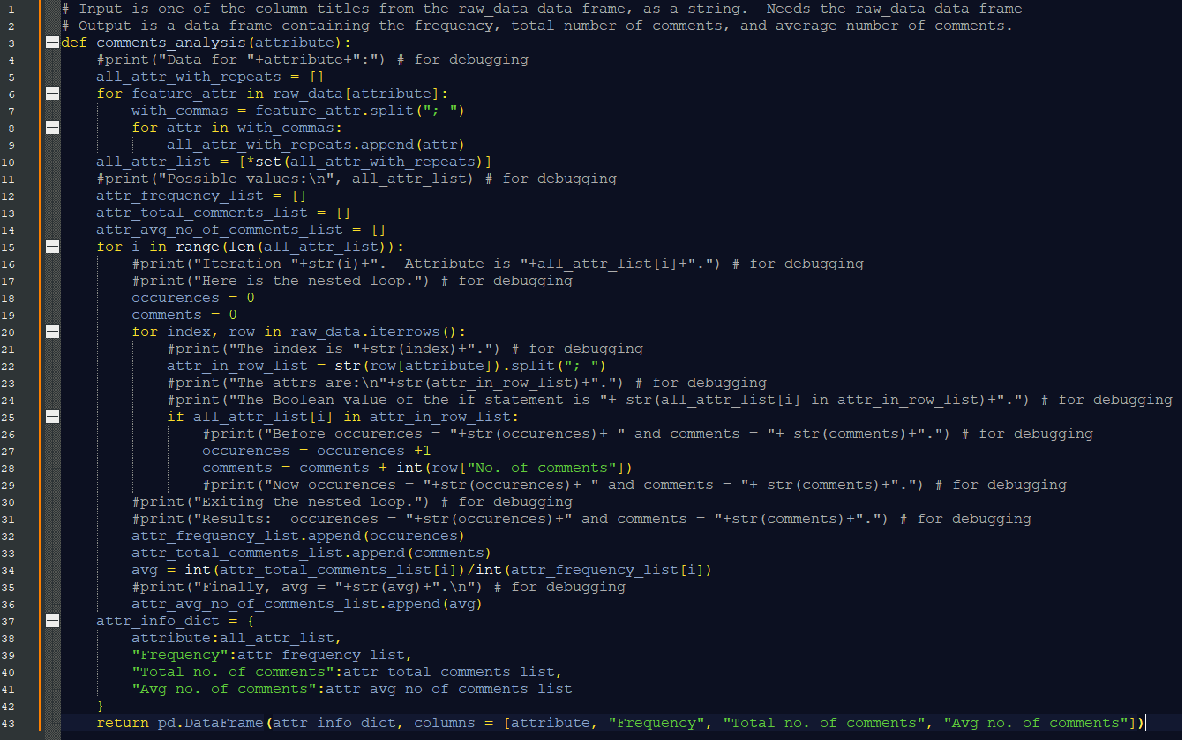
So last night, I wrote code that would make a list of all tags used in the 50 posts, then create a data frame where for each tag I would have the number of times the tag was used, the total number of comments from posts where it was used, and the average number of comments per post where it was used. Writing code to do that turned out to be pretty simple, even with all the debugging I had to do. I didn’t use the timer this time, since the script ran pretty fast, but I did include a lot of print statements giving me the progress of how my code was compiling. I decided in all my code for this project I should include a comment – “for debugging” – on all the lines of code where I have print statements or timers, rather than outright delete that code once everything is compiling correctly. I thought keeping that code would be useful to those who want to run my code for themselves, and see how it works.
Once I got all the data for the tags, I put it in a new data frame. I was really surprised at how easy it was to do. I think writing the code would’ve been even faster if I was more proficient with python, and didn’t have to use Google so much to find functions that would do the basic tasks I wanted to do. For example, I knew how to make a data frame using a list of rows, but not how to make one using a list of columns, which is what I had. It turns out, there are a couple of ways to do it: one way uses a transpose function that I knew about, and the other way uses a dictionary. I decided to use a dictionary. I’d known about them, but I had never used one before.
In my project problem statement, I’d said I only wanted to analyze the tags on the content on 538 against the comments. But I’d been thinking I should do a similar analysis on the authors and types of content: podcast, video, article. When I saw how easy it was to do for the tags, I realized the code to do this would be nearly identical to the code I used for the tags. I’d asked Matt before if I should write more functions in my data gathering code to make it easier to read, but he said really I only need to write functions if I find myself copying chunks of code. This was definitely an instance where I needed to write the function. It was kind of late last night when I thought to do it, and it seemed daunting. But then it took less than half an hour to do! The code I’d written for the tags was very easy to generalize. I called the function for the authors and for the types of posts, and very quickly got everything I needed! Because it was so much easier than I expected, I thought I should modify my problem statment to include analysis of the authors and types of content.
I told myself not to include too many long snippets of code in my blog posts, but I have to post this function. I’ve been using Jupyter notebooks to run all of my python, but I decided when I post code on this blog the most attractive way is to paste it into a Notepad++ file then screenshot. Markdown’s code environments are kind of ugly, and Notepad++ has great syntax highlighting. Maybe I should see if there is a plugin for Notepad++ that will allow me to compile python code. I know in the past I’ve been able to set it up to compile LaTeX (and PlainTeX!). Matt also said that when I get my 500 posts of data, if I’m afraid of the Jupyter kernel crashing, then there is a way to compile python in the command line. I’m a little intimidated by that, so for now I just changed my computer settings to not go to sleep, just to prevent the Jupyter kernel from crashing because of that. Anyway, here is the function: